大家好,我是苏三,又跟大家见面了。文末留言送书啦!!!前言最近在我的知识星球中,有个小伙伴问了这样一个问题:百万商品分页查询接口,如何保证接口的性能?这就需要对该分页查询接口做优化了。这篇文章从9个方面跟大家一起聊聊分页查询接口优化的一些小...
A股板块轮动加剧,跨年大妖来袭,这几只票主力已明显介入!微信搜索关注【研讯小组】公众号(可长按复制),回复666,领取代码!
文末留言送书啦!!!
最近在我的知识星球中,有个小伙伴问了这样一个问题:百万商品分页查询接口,如何保证接口的性能?
这就需要对该分页查询接口做优化了。
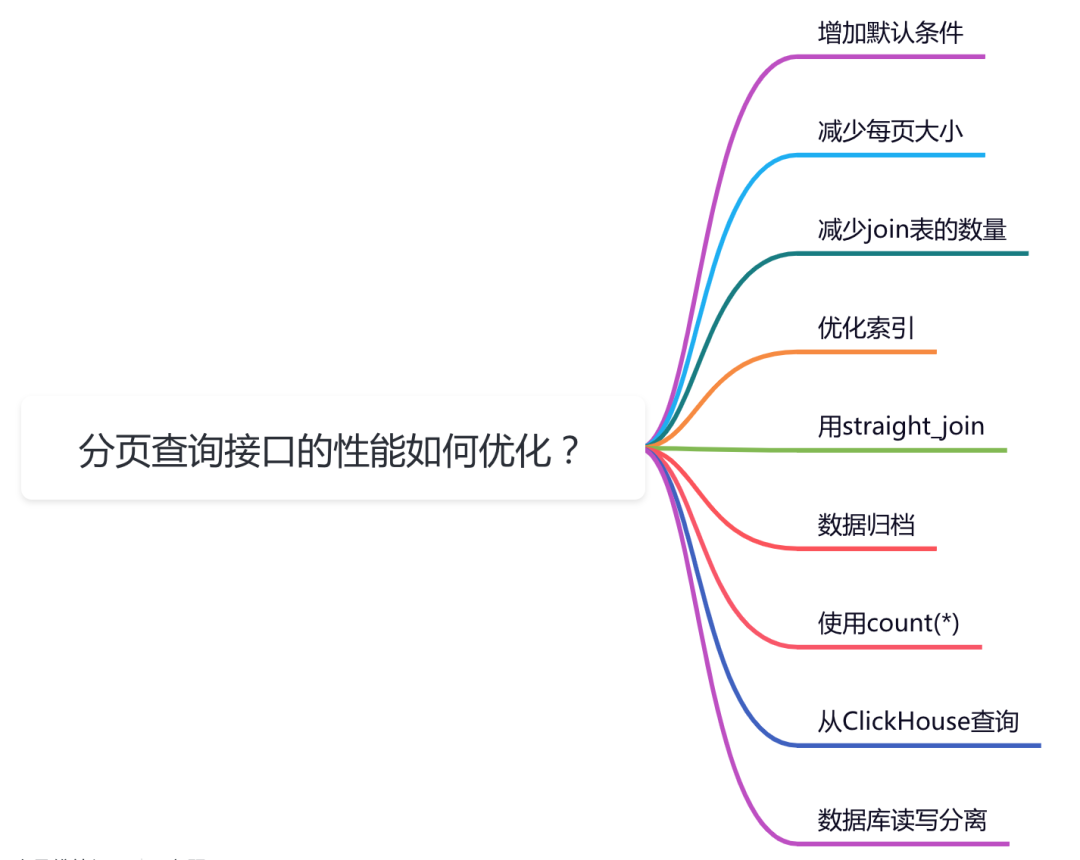
这篇文章从9个方面跟大家一起聊聊分页查询接口优化的一些小技巧,希望对你会有所帮助。
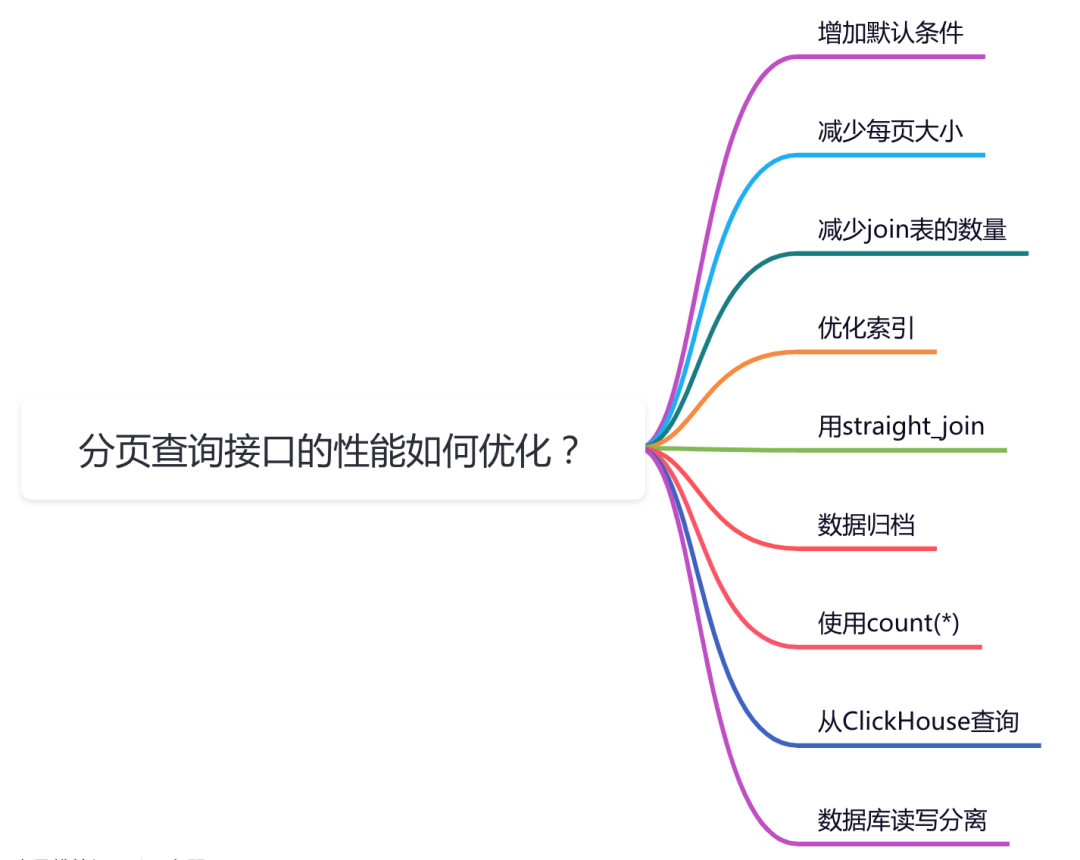
对于分页查询接口,如果没有特殊要求,我们可以在输入参数中,给一些默认值。
这样可以缩小数据范围,避免每次都count所有数据的情况。
对于商品查询,这种业务场景,我们可以默认查询当天上架状态的商品列表。
例如:
select*fromproduct
whereedit_date>='2023-02-20'andedit_date<'2023-02-21'andstatus=1
如果每天有变更的商品数量不多,通过这两个默认条件,就能过滤掉绝大部分数据,让分页查询接口的性能提升不少。
温馨提醒一下:记得给
时间和状态字段增加一个联合索引。
分页查询接口通常情况下,需要接收两个参数:pageNo(即:页码)和pageSize(即:每页大小)。
如果分页查询接口的调用端,没有传pageNo默认值是1,如果没有传pageSize也可以给一个默认值10或者20。
不太建议pageSize传入过大的值,会直接影响接口性能。
在前端有个下拉控件,可以选择每页的大小,选择范围是:10、20、50、100。
前端默认选择的每页大小为10。
不过在实际业务场景中,要根据产品需求而且,这里只是一个参考值。
有时候,我们的分页查询接口的查询结果,需要join多张表才能查出数据。
比如在查询商品信息时,需要根据商品名称、单位、品牌、分类等信息查询数据。
这时候写一条sql可以查出想要的数据,比如下面这样的:
select
p.id,
p.product_name,
u.unit_name,
b.brand_name,
c.category_name
fromproductp
innerjoinunituonp.unit_id=u.id
innerjoinbrandbonp.brand_id=b.id
innerjoincategoryconp.category_id=c.id
wherep.name='测试商品'
limit0,20;
使用product表去join了unit、brand和category这三张表。
其实product表中有unit_id、brand_id和category_id三个字段。
我们可以先查出这三个字段,获取分页的数据缩小范围,之后再通过主键id集合去查询额外的数据。
我们可以把sql改成这样:
select
p.id,
p.product_id,
u.unit_id,
b.brand_id,
c.category_id
fromproduct
wherename='测试商品'
limit0,20;
这个例子中,分页查询之后,我们获取到的商品列表其实只要20条数据。
再根据20条数据中的id集合,获取其他的名称,例如:
selectid,name
fromunit
whereidin(1,2,3);
然后在程序中填充其他名称。
伪代码如下:
List
List
List
for(Productproduct:productList){
Optional
if(optional.isPersent()){
product.setUnitName(optional.get().getName());
}
}
这样就能有效的减少join表的数量,可以一定的程度上优化查询接口的性能。
分页查询接口性能出现了问题,最直接最快速的优化办法是:优化索引。
因为优化索引不需要修改代码,只需回归测试一下就行,改动成本是最小的。
我们需要使用explain关键字,查询一下生产环境分页查询接口的执行计划。
看看有没有创建索引,创建的索引是否合理,或者索引失效了没。
索引不是创建越多越好,也不是创建越少越好,我们需要根据实际情况,到生产环境测试一下sql的耗时情况,然后决定如何创建或优化索引。
建议优先创建联合索引。
如果你对explain关键字的用法比较感兴趣,可以看看我的这篇文章《explain | 索引优化的这把绝世好剑,你真的会用吗?》。
如果你对索引失效的问题比较感兴趣,可以看看我的这篇文章《聊聊索引失效的10种场景,太坑了》。
有时候我们的业务场景很复杂,有很多查询sql,需要创建多个索引。
在分页查询接口中根据不同的输入参数,最终的查询sql语句,MySQL根据一定的抽样算法,却选择了不同的索引。
不知道你有没有遇到过,某个查询接口,原本性能是没问题的,但一旦输入某些参数,接口响应时间就非常长。
这时候如果你此时用explain关键字,查看该查询sql执行计划,会发现现在走的索引,跟之前不一样,并且驱动表也不一样。
之前一直都是用表a驱动表b,走的索引c。
此时用的表b驱动表a,走的索引d。
为了解决Mysql选错索引的问题,最常见的手段是使用force_index关键字,在代码中指定走的索引名称。
但如果在代码中硬编码了,后面一旦索引名称修改了,或者索引被删除了,程序可能会直接报错。
这时该怎么办呢?
答:我们可以使用straight_join代替inner join。
straight_join会告诉Mysql用左边的表驱动右边的表,能改表优化器对于联表查询的执行顺序。
之前的查询sql如下:
selectp.idfromproductp
innerjoinwarehousewonp.id=w.product_id;
...
我们用它将之前的查询sql进行优化:
selectp.idfromproductp
straight_joinwarehousewonp.id=w.product_id;
...
随着时间的推移,我们的系统用户越来越多,产生的数据也越来越多。
单表已经到达了几千万。
这时候分页查询接口性能急剧下降,我们不能不做分表处理了。
做简单的分表策略是将历史数据归档,比如:在主表中只保留最近三个月的数据,三个月前的数据,保证到历史表中。
我们的分页查询接口,默认从主表中查询数据,可以将数据范围缩小很多。
如果有特殊的需求,再从历史表中查询数据,最近三个月的数据,是用户关注度最高的数据。
在分页查询接口中,需要在sql中使用count关键字查询总记录数。
目前count有下面几种用法:
count(1)
count(id)
count(普通索引列)
count(未加索引列)
那么它们有什么区别呢?
count(*) :它会获取所有行的数据,不做任何处理,行数加1。
count(1):它会获取所有行的数据,每行固定值1,也是行数加1。
count(id):id代表主键,它需要从所有行的数据中解析出id字段,其中id肯定都不为NULL,行数加1。
count(普通索引列):它需要从所有行的数据中解析出普通索引列,然后判断是否为NULL,如果不是NULL,则行数+1。
count(未加索引列):它会全表扫描获取所有数据,解析中未加索引列,然后判断是否为NULL,如果不是NULL,则行数+1。
由此,最后count的性能从高到低是:
count(*) ≈ count(1) > count(id) > count(普通索引列) > count(未加索引列)
所以,其实count(*)是最快的。
我们在使用count统计总记录数时,一定要记得使用count(*)。
有些时候,join的表实在太多,没法去掉多余的join,该怎么办呢?
答:可以将数据保存到ClickHouse。
ClickHouse是基于列存储的数据库,不支持事务,查询性能非常高,号称查询十几亿的数据,能够秒级返回。
为了避免对业务代码的嵌入性,可以使用Canal监听Mysql的binlog日志。当product表有数据新增时,需要同时查询出单位、品牌和分类的数据,生成一个新的结果集,保存到ClickHouse当中。
查询数据时,从ClickHouse当中查询,这样使用count(*)的查询效率能够提升N倍。
需要特别提醒一下:使用ClickHouse时,新增数据不要太频繁,尽量批量插入数据。
其实如果查询条件非常多,使用ClickHouse也不是特别合适,这时候可以改成ElasticSearch,不过它跟Mysql一样,存在深分页问题。
有时候,分页查询接口性能差,是因为用户并发量上来了。
在系统的初期,还没有多少用户量,读数据请求和写数据请求,都是访问的同一个数据库,该方式实现起来简单、成本低。
刚开始分页查询接口性能没啥问题。
但随着用户量的增长,用户的读数据请求和写数据请求都明显增多。
我们都知道数据库连接有限,一般是配置的空闲连接数是100-1000之间。如果多余1000的请求,就只能等待,就可能会出现接口超时的情况。
因此,我们有必要做数据库的读写分离。写数据请求访问主库,读数据请求访问从库,从库的数据通过binlog从主库同步过来。
根据不同的用户量,可以做一主一从,一主两从,或一主多从。
数据库读写分离之后,能够提升查询接口的性能。
如果你对性能优化比较感兴趣,可以看看《性能优化35讲》,里面有更多干货内容。
为了感谢一路支持苏三的小伙们,今天特地给大家送一点小福利。规则非常简单:在本文留言,按点赞数量排名,点赞数量最多的前3位,每人获取1本书。(你可以发朋友圈集赞,或者发微信群集赞。但如果发现有人用机器刷点赞数,立即取消资格,并且拉黑)
后面我会朋友圈公布中奖名单,给你免费包邮到家!这些书是由清华大学出版社提供的,感谢赞助。

《深入理解分布式共识算法》结合理论知识、算法模拟和源码解析,从多个维度详细剖析分布式共识算法的基本原理和应用实践,涵盖分布式共识算法的方方面面。同时《深入理解分布式共识算法》对共识算法开发中的重点和难点问题进行了重点讲解,并提供精心准备的练习题供读者巩固和提高所学的知识。另外,作者针对重点内容录制了教学视频,以帮助读者高效、直观地学习。
《深入理解分布式共识算法》共10章,分为4篇。第1篇分布式相关概念与定理,主要介绍集群、状态机和共识等相关概念,以及BASE和CAP理论等相关知识;第2篇常见分布式共识算法原理与实战,主要介绍二阶段提交(2PC)协议、三阶段提交(3PC)协议、Paxos、ZAB和Raft等相关知识;第3篇Paxos变种算法集合,主要介绍Paxos变种算法的发展历程,以及Fast Paxos和EPaxos等变种算法的相关知识;第4篇番外——FLP 定理,简要介绍FLP定理的相关知识。《深入理解分布式共识算法》按照“背景知识→运行过程→算法模拟→证明脉络”的过程层层推进,介绍算法知识,并为每种算法提供经典类库源码解析。
如果这篇文章对您有所帮助,或者有所启发的话,帮忙扫描下发二维码关注一下,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:面试、代码神器、开发手册、时间管理有超赞的粉丝福利,另外回复:加群,可以跟很多BAT大厂的前辈交流和学习。
A股板块轮动加剧,跨年大妖来袭,这几只票主力已明显介入!微信搜索关注【研讯小组】公众号(可长按复制),回复666,领取代码!
本站内容转载请注明来源并提供链接,数据来自互联网,仅供参考。如发现侵权行为,请联系我们删除涉嫌侵权内容。

你合并代码用 merge 还是用 rebase ?(苏三说技术2024年08月01日文章)
阿里云盘,出现灾难级Bug(苏三说技术2024年09月16日文章)
突发,EasyExcel宣布停更了!(苏三说技术2024年11月10日文章)
Mysql很慢,除了索引,还能因为什么?(苏三说技术2024年07月29日文章)
架构师必须懂这些。。。(苏三说技术2024年10月31日文章)
几行烂代码,用错Transactional,赔了16万。(苏三说技术2024年07月30日文章)
架构师必须掌握这些技术。。。(苏三说技术2024年08月31日文章)
瞧瞧别人家的异常处理,那叫一个优雅(苏三说技术2024年10月24日文章)
阿里神器 Seata(苏三说技术2024年10月19日文章)
裁员了,很严重,大家做好准备吧!(苏三说技术2024年09月04日文章)


版权投诉请发邮件到1191009458#qq.com(把#改成@),我们会尽快处理
Copyright©2023-2024众股360(www.zgu360.com).AllReserved|备案号:湘ICP备2023009521号-3
本站资源均收集整理于互联网,其著作权归原作者所有,如有侵犯你的版权,请来信告知,我们将及时下架删除相应资源
Copyright © 2024-2024 EYOUCMS. 易优CMS 版权所有 Powered by EyouCms

每日深度解析主力最新动作
挖掘主力即将拉升方向和个股




